User Guide – Introduction
OCR4all is a software which is primarily geared towards the digital text recovery and recognition of early modern prints, whose elaborate printing types and mostly uneven layout challenge the abilities of most standard text recognition software. The workflow established by OCR4all isn’t only easy to understand, but it also allows for an independent use, which makes it particularly suitable for users with no background in computer sciences, in part because it combines different tools into one consistent user interface. Constant switching between different software platforms is thereby rendered obsolete.
OCR4all contains a complete and exhaustive OCR workflow, starting with the pre-processing of the images in question (Preprocessing), followed by layout segmentation (Region Segmentation, done with LAREX), the extraction of classified layout regions and line segmentation (Line Segmentation), text recognition (Recognition) and ending with the correction of the textual end product (Ground Truth Production) – all the while developing OCR models adapted to specific printed texts (fig. 1).
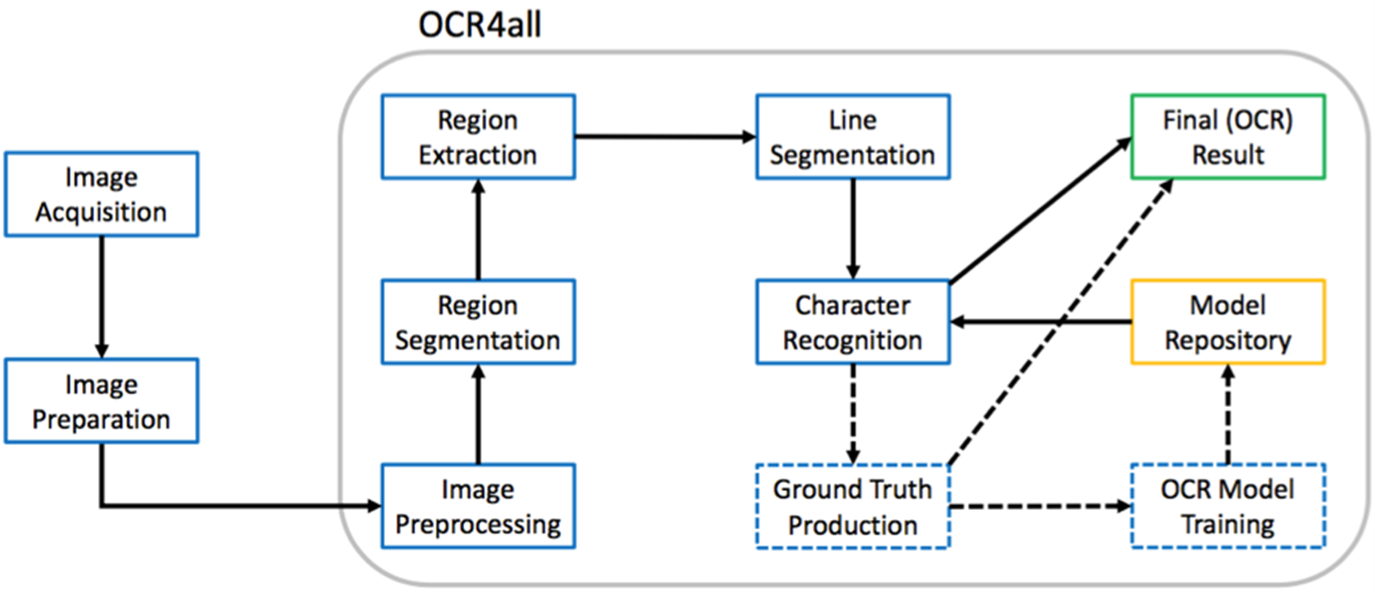 fig. 1. Principal components of the OCR4all workflow.
fig. 1. Principal components of the OCR4all workflow.
In part thanks to the possibility of developing and training book-specific recognition models – which can then theoretically be applied to other prints – OCR4all produces very good results when it comes to the digital recognition of about any printed text.
The following guide aims to provide an exhaustive and detailed look into OCR4all’s operation and fields of application concerning the recognition of particularly early prints. While chapter 1 covers the software’s set up and folder structure, chapter 2 concentrates on the recommended pre-processing of scans and image data, a step which occurs outside OCR4all and leads not only to a visible improvement of the results but facilitates the different steps within the OCR4all workflow. Chapter 3 focuses on starting the software and presenting its basic functions. It is followed, in chapter 4, by a detailed, step-by-step description of the different stages of the workflow, introducing the actual processing of prints and generation of the OCR text. Finally, chapter 5 takes on the most common user problems currently known.